Alice in Kernel Land: eBPF rabbit hole


What is eBPF?
eBPF stands for (extended Berkeley Packet Filter). eBPF is the new version of a technology called BPF, which is a bytecode VM designed to run in kernel to analyze network traffic and provide filtering capabilities. eBPF extends BPF implementation with a lot of added functionality to call kernel functions. Although eBPF has its roots in packet filtering, it has now developed so much more functionalities that the acronym no longer makes sense. eBPF is therefore a revolutionary technology that can run sandboxed programs in a privileged context such as the operating system kernel. It is used to safely and efficiently extend the capabilities of the kernel without requiring to change kernel source code or load kernel modules. This ability to modify dynamically how the kernel behaves is what brings superpowers to the Linux kernel.
eBPF is like JavaScript but for the kernel.
Just as JavaScript can be executed on an arbitrary event (e.g. button click) on a web application, eBPF can be executed in the kernel in the operating system on event triggers (e.g. a system call).
Why eBPF?
The biggest problem the Linux kernel has today is that innovation is really slowed down because Linux is running everywhere: smartphones, servers, embedded devices, etc. This is why the Linux kernel has to be very stable. Normally, changes in kernel behavior would require kernel modules to extend functionality. Kernel modules are difficult to maintain because there are changes with each kernel revision that can often break compatibility. Also, fiddling with kernel modules is not recommendable as it could introduce bugs in kernel space which can be fatal. This slows down kernel development significantly. The Linux kernel has over 30 million lines of code and making a change can take months or even years just to get it merged upstream, thus decreasing the rate of innovation. On the other hand, the operating system has always been an ideal place to implement observability, security, and networking functionality due to the kernel’s privileged ability to oversee and control the entire system.
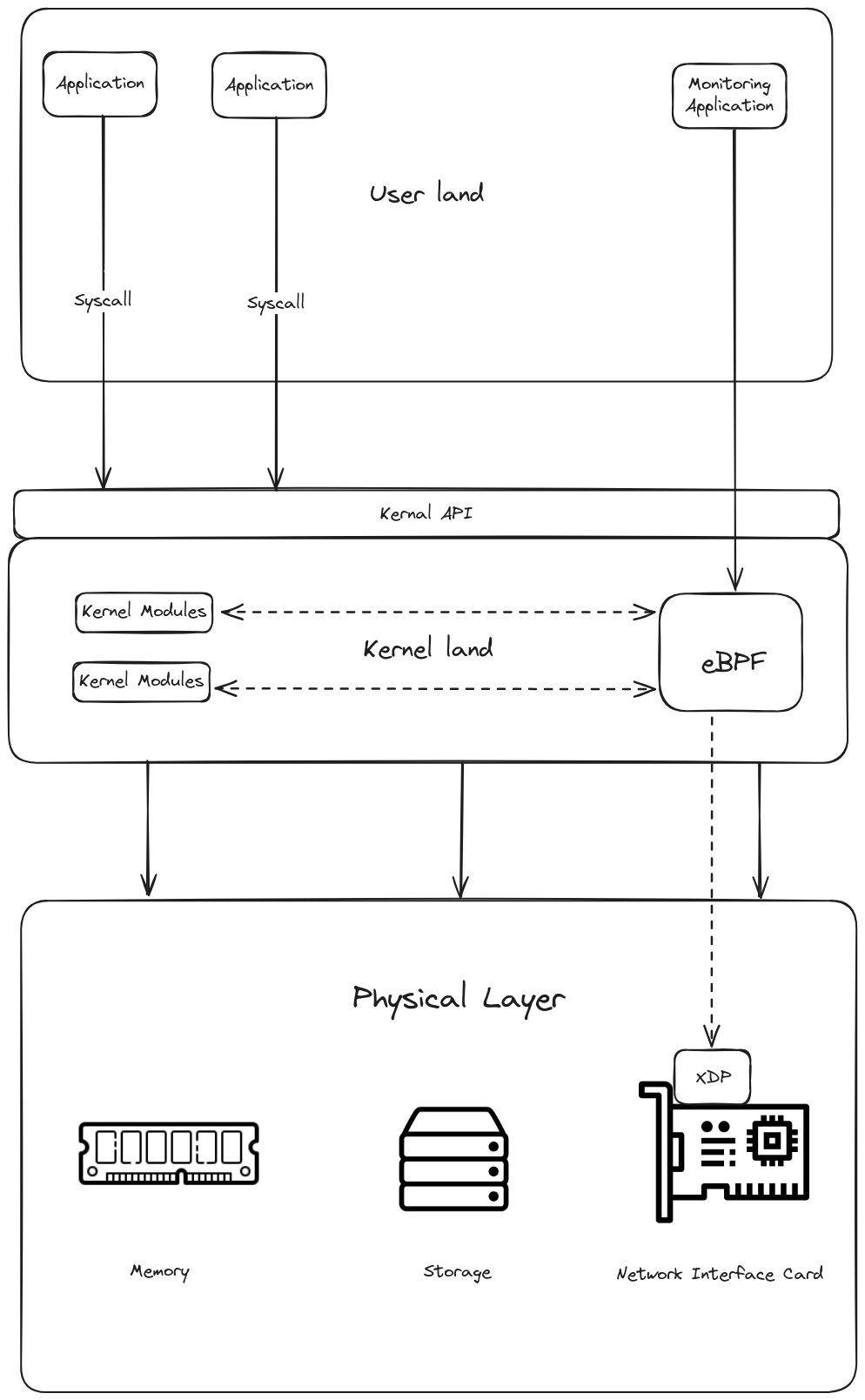
eBPF is changing that by making the Linux kernel programmable in a safe and efficient manner. It allows us to add code in the operating system to change the behavior of the kernel and implement functionality dynamically, which makes execution up to 10x faster and more efficient. It can even interact with internal operating system APIs not available in user space. eBPF therefore allows extensibility at a layer where normally it would be very difficult to implement. This has led to a wave of eBPF-based projects covering a wide array of use cases, including next-generation networking, observability, and security functionality. With eBPF, you can isolate the risk and extend kernel functionality safely. You also do not need to recompile the kernel and restart the system to deploy or revert changes in eBPF applications. A further advantage of eBPF is that we do not need to poll for the events that we are interested in monitoring, our program will automatically be run via hooks when the event is triggered.
As eBPF runs inside the kernel, it has significant performance advantages than running applications in user space that would invoke system calls on the kernel API. The overhead of context switching between user space and kernel space is too much to run monitoring and network filtering tools. In addition, there is an upper limit to the rate of system calls allowed which may be the bottleneck for many high intensive monitoring applications. eBPF can make early decisions receiving input from devices the kernel is managing and allows installing hooks into any of these devices and these hooks can have links back to programs running in user space.
eBPF was historically only in the Linux kernel, but due to its advantages and use cases, it is not Linux-specific anymore, as it has also been successfully ported to Windows by Microsoft.
Use cases
There are many projects around observability and traffic monitoring that have proven how powerful this technology is.
- Network Filtering - eBPF can enforce network rules such as egress filtering for loss prevention or content filtering in the kernel level. It is also used for inspecting packets, modifying network packets on the fly or rerouting them.
- Observability - eBPF can see traffic from any device on the server and the behavior of any process in the process tree. As applications are broken down into microservices, it becomes increasingly difficult to implement observability in user land. Using eBPF, it allows user space processes such as system monitor, network monitor and tracing tools to have kernel space point of view. This is an alternative to service meshes that use distributed tracing using sidecar proxies, which each add performance burden on the system. Instead, performing this at the kernel level is advantageous for improving overall system performance.
- Security policies - You can use network filtering and observability to enforce policies by for example asking the kernel to kill processes, filter/drop network traffic or permitting/restricting certain behaviors.
Today, eBPF is used extensively to drive a wide variety of use cases: Providing high-performance networking and load-balancing in modern data centers and cloud native environments, extracting fine-grained security observability data at low overhead, helping application developers trace applications, providing insights for performance troubleshooting, preventive application and container runtime security enforcement, and much more.
Many of the US hyperscalers—Meta, Google, Netflix–use eBPF in production. Facebook (Meta) is using eBPF for load-balancing. Every single packet that goes in and out of a Meta data center is touched by eBPF. All major cloud providers use eBPF-based networking and security for their managed Kubernetes platforms (GKS, EKS, AKS). Even smartphones are using eBPF. Android uses eBPF programs to do traffic accounting to find out how much CPU, memory or network each app uses. It is very useful to monitor network volume, TLS-handshakes and HTTP-traces without any sidecars and proxies. It can also be used to display process trees to analyze how applications behave and what commands they execute, which can be used to detect malicious software.
eBPF introduces a number of different possibilities that were previously difficult to scale at the same pace of application modernization. Solutions that take advantage of eBPF will be able to provide high degree of functionality without the challenges of performance degradation and kernel instability.
Working mechanism
The communications between the user space and kernel space happen in events. eBPF is therefore also event-driven. It can be run when the kernel or an application passes a certain hook point. Pre-defined hooks include system calls, function entry/exit, kernel tracepoints, network events, and several others. Hardware events are hookable as well. Furthermore, depending upon the network interface, some of the network events can be processed on the network interface itself using XDP, instead of using the CPU! This allows for very fast filtering of network packets using eBPF. If a predefined hook does not exist for a particular need, it is possible to create a kernel probe (kprobe) or user probe (uprobe) to attach eBPF programs almost anywhere in kernel or user applications.
- kprobes: kprobes enables you to dynamically break into any kernel routine and collect debugging and performance information non-disruptively. You can trap at almost any kernel code address, specifying a handler routine to be invoked when the breakpoint is hit.
- uprobes: uprobes is similar to kprobes, but for user space memory.
eBPF consists of a language and a runtime. eBPF can be expressed in a variety of different languages: pseudo-C, Go, Rust, C++. However, there are very strict safety requirements to be followed as they run in the kernel, which is the most critical part of the system. The verifier makes sure that the code isn't doing something unwanted intentionally or accidentally. For example, infinite loops, recursion and jumping to instructions are strictly prohibited. The process of executing an eBPF program is as follows:
- Our program that we write in high level programming language needs to be compiled into eBPF bytecode (e.g. using BCC for Python or LLVM Compiler for C, etc.).
- eBPF Verifier makes sure that our program is safe to run. It checks whether the process loading the eBPF program holds the required privileges, does not crash and that it always runs to completion.
- eBPF Just-In-Time (JIT) compiler compiles the generic bytecode into the machine specific instruction set to optimize execution speed of the program and attaches them to hooks. This makes eBPF programs run as efficiently as natively compiled kernel code or as code loaded as a kernel module.
To collect data collected by eBPF programs back into user space, eBPF provides eBPF Maps where we can store data in various formats such as hashmap, array, stacktrace, ring buffer and many more. eBPF Map is a storage located inside the kernel. eBPF provides syscalls to user space, which can be used to retrieve data stored in eBPF Map. This is actually a bidirectional map, so user space programs can update that and send input to the kernel!
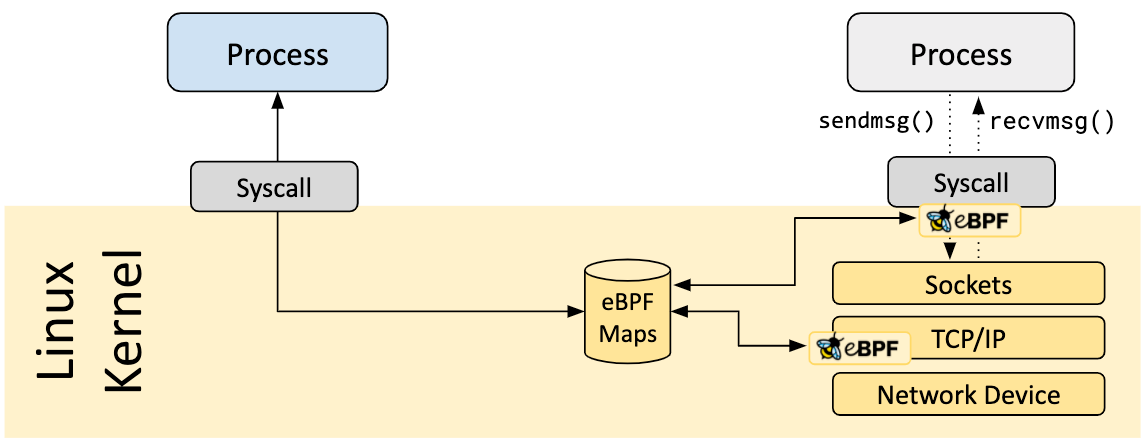
The declaration of BPF Maps takes in the following parameters:
- eBPF Map Type
- Max number of elements
- Key size (in bytes)
- Value size (in bytes)
Of course eBPF programs cannot call into arbitrary kernel functions. Allowing this would bind eBPF programs to particular kernel versions and would complicate compatibility of programs. Instead, eBPF programs can make function calls into helper functions, a well-known and stable API offered by the kernel.
Working with eBPF
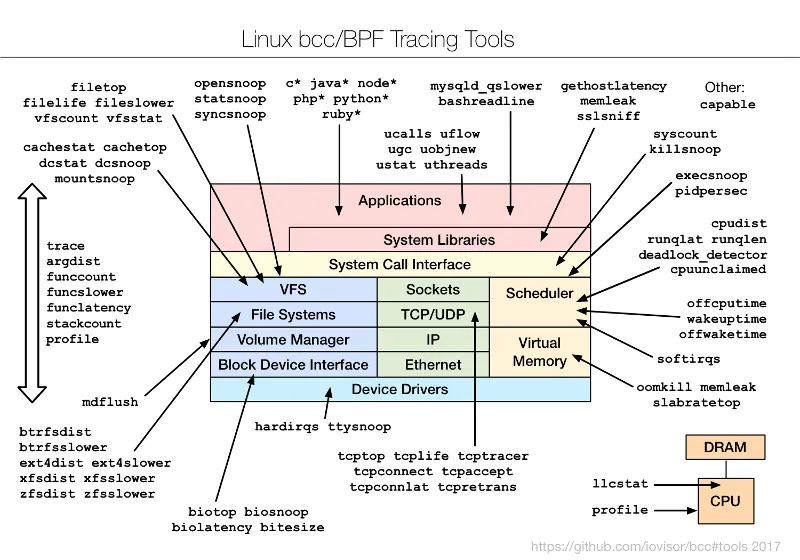
BCC (BPF Compiler Collection) is a collection of tools and helpers for developing eBPF programs. BCC has a lot of ready-to-use command line interfaces which are built using eBPF. It also allows building programs using Python library. It is mainly used for application and system profiling/tracing where an eBPF program is used to collect statistics or generate events and a counterpart in user space collects the data and displays it in a human readable form.
bpftrace is a high-level tracing language for Linux eBPF. bpftrace uses LLVM as a backend to compile scripts to eBPF bytecode and makes use of BCC for interacting with the Linux eBPF subsystem as well as existing Linux tracing capabilities: kernel dynamic tracing (kprobes), user-level dynamic tracing (uprobes), and tracepoints.
Installing BCC
The installation instructions for BCC can be found at https://github.com/iovisor/bcc/blob/master/INSTALL.md#ubuntu---binary
The following instructions can be used to install BCC on Ubuntu 22.04.
$ git clone https://github.com/iovisor/bcc.git
$ sudo apt install -y zip bison build-essential cmake flex git libedit-dev \
libllvm14 llvm-14-dev libclang-14-dev python3 zlib1g-dev libelf-dev libfl-dev python3-setuptools \
liblzma-dev libdebuginfod-dev arping netperf iperf
mkdir bcc/build; cd bcc/build
$ cmake ..
$ make
$ sudo make install
$ cmake -DPYTHON_CMD=python3 .. # build python3 binding
$ pushd src/python/
$ make
$ sudo make install
$ popd
BCC provides a whole host of tools which can be used to make BPF programs, as shown by the following figure.
bpftrace example
Installing bpftrace on Ubuntu 22.04
$ sudo apt-get install -y bpftraceThe following code finds every execution of a binary on the system and joins the array of arguments for that executable and prints it on the console.
$ sudo bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'The following code is using the syscall tracepoint to trace PID and filepath.
$ bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%d %s\n", pid, str(args->filename)); }'eBPF Tools
There are many tools emerging that takes advantages of the capabilities provided by eBPF. Here are some of the tools widely used as of today. Cilium and Hubble provide networking and observability features for bare-metal as well as Kubernetes platform. Falco is a behavioral activity monitor designed to detect anomalous activity in applications. Pixie is an open source observability tool for Kubernetes applications that uses eBPF to automatically capture telemetry data. Tetragon provides eBPF-based transparent security observability combined with real-time runtime enforcement. Kubectl trace is used for tracing in Kubernetes. Pulsar is a security tool for monitoring the activity of Linux devices at runtime. Calico is a pluggable eBPF-based networking and security for containers and Kubernetes.
Disadvantages
- Security: As eBPF is running inside the kernel, it will have a lot of capabilities that normal programs don't get. While there are lot of development going on to secure eBPF, there is a parallel race to develop Rootkits that try to exploit eBPF to gain malicious access to systems.
- Performance trade-offs: Doing too many things with eBPF may end up hampering overall system performance as a CPU can only do a certain number of operations per second. Users then need to pick which subset of features to enable to optimize performance.
- Co-existence: If a kernel has two eBPF programs and they both want to work on the same packet, it needs to be decided who goes first so that they don't step on each other's toes.
- Kernel expertise: eBPF exposes the internals of Linux kernel to applications. This means that programming eBPF requires deep kernel expertise.
EBPF Foundation
Early on, eBPF was a technology only consumable by Linux developers because it was so complicated and so few people have expertise with the Linux kernel. Then the hyperscalers—Google, Facebook, Netflix, etc., — jumped in. They had the engineering might to develop the technology, as well as the expertise and control of their systems to use it, roll it out, and make improvements.
The eBPF Foundation was created in August 2021 with the goal to expand the contributions being made to extend the powerful capabilities of eBPF and grow beyond Linux. Founding members include Meta, Google, Isovalent, Microsoft and Netflix. The purpose is to raise, budget and spend funds in support of various open source, open data and/or open standards projects relating to eBPF technologies to further drive the growth and adoption of the eBPF ecosystem. Since inception, Red Hat, Huawei, Crowdstrike, Tigera, DaoCloud, Datoms, FutureWei also joined.
They’ve led the charge with eBPF in production, meaning it probably touches the lives of almost every digital consumer today.
Happy Hacking!